- Details
- Written by: Douglas Berry
- Category: Pythagorean
- Hits: 598
Customer Life Time Value Forecast With BYDT
- Details
- Written by: Douglas Berry
- Category: Pythagorean
- Hits: 1268
Quantifying Decisions Under Uncertainty
There are modeling approaches for predicting outcomes under low uncertainty settings and a different modeling approach for predicting outcomes under high uncertainty. Linear programming, under low uncertainty settings, allows us to calculate an objective function and determine if the solution is feasible based on resource constraints. For high uncertainty settings we need to calculate the distribution for the key performance indicators and compare the distributions of outcomes.
Steps to calculate the distribution of the sales performance KPI for a product under high levels of uncertainty:
- Define the KPI: Total number of units sold.
- Collect data: Collect data on the total number of units sold over a month.
- Calculate the average: Calculate the average number of units sold per day.
- Calculate the standard deviation: Calculate the standard deviation of the number of units sold per day.
- Plot the distribution: Plot the distribution of the number of units sold per day using a histogram or a box plot.
Roadmap for making decisions in high uncertainty environments:
- Confirm risk and reward measures
- Use simulation for each competing decision to estimate reward and risk measures via a distribution:
- Normal distribution
- Bernoulli
- Binomial
- Poisson
- Patterned
- Discrete
- Optimize reward (Demand Volume) as an objective function with risk measures as constraints
- Results of the simulations can be fed into an optimizer forming an effective management decisioning tool set

Digital Twins
A digital twin is a virtual representation of a physical object or system that is updated in real-time using data from sensors and other sources. It uses simulation, machine learning, and reasoning to help decision making. Digital twins are used to simulate the behavior of physical objects, systems, or processes to better understand how they work in real life. They can be used to study performance issues, generate possible improvements, and create valuable insights, which can then be applied back to the original physical object. There are various types of digital twins depending on the level of product magnification, such as component twins, parts twins, asset twins, and system or unit twins. Digital twins are used in various industries and applications, such as manufacturing, healthcare, and transportation.
Simulation of Manufacturing Processes
SAP HANA is an in-memory database and application development platform that provides real-time data processing and analytics capabilities. R is a popular open-source programming language for statistical computing and graphics. SAP HANA provides integration with R through the RLANG procedure, which allows embedding R code in SAP HANA SQL code and execute it using the external R environment. We use R to perform statistical analysis, data mining, and machine learning on data stored in SAP HANA.
Additionally, R is software tool used to simulate manufacturing processes, that is to create a Digital Twin. We use a simulation package in R for discrete-event simulation that allows us to create statistical variables required for simulation, define process trajectory, define and assign resources, define arrivals, run simulation in R, store results in data frames, plot charts, and interpret the results.
To simulate a manufacturing process, working with your organization, TekMetrix will create process maps, gather data, build and test the simulation mathematical models, and work with your organization to analyze and interpret the results.
Delivery Methods
- Build a virtual representation of the supply chain using R or equivalent
- Select the simulation technique:
- Enterprise modeling and simulation - create a Digital Twin of the manufacturing system to optimize various aspects of production planning, inventory management and resource allocation
- Data-driven simulation - using data and analytics with machine learning create a predictive model of the manufacturing system to optimize production scheduling, quality control and maintenance
- Process simulation - simulate individual business processes within the manufacturing system to identify bottlenecks, optimize resource alloction and improve efficiency
- Agent-based simulation - simulate the behavior of individual agents within the manufacturing system such as unit operations, machines, workers and customers to optimize production scheduling, resource allocation and customer service
- Discrete event simulation - simulate the flow of discrete events within the manufacturing system such as the arrival of raw materials, processing of parts and shipment of finished goods. Businesses can optimize various aspects of production scheduling, inventory management and quality control
- Monte Carlo - model project timelines seeking to optimize resources and used for financial forecasting
- Dynamic simulations - time based simulation models coded as solutions to partial differential equations.
- Engage TekMetrix Supply Chain Diagnostics
- Optimize customer value by leveraging innovation, transparency, efficiency and resillence in the supply chain
- Find new sources of innovation and value creation using the simulations
- Create sustainable value for your organization
- Details
- Written by: Douglas Berry
- Category: Pythagorean
- Hits: 716
Optimizing Decisions
Prescriptive analytics seeks to analyze, for example, past consumer behavior to predict future behavior. Prescriptions are recommendations. Therefore, how do we define a prescriptive problem, how to set goals and objectives, how can the company optimize the goals and objectives, what actions can a company take to affect the outcome of their goals and how do companies respond to other companies actions?
The market structure needs to be a part of the model. If the company takes an action, for example, price change of the product, then how do other companies in the market respond? These are the questions that prescriptive analytics will answer. Willingness to pay (WTP) measures the maximum amount a customer is willing to pay for an incremental purchase of a product or service. WTP is calculated as:
WTP = ((New Price + Old Price) * Price Increment)/2 = > Trapezoidal Rule
TekMetrix WTP solutions improve brand performance by:
- Predicting market demand
- Setting channel prices
- Making formulation decisions
- Determining promotional spend strategy
- Communications strategy
- Creating dashboards and reports
- Determine the relationship between variables
- Understand why and how issues occur
- Create an interative process between analytic and decision making
- Make decisions
- Units to produce
- Channel price
- Formulation
- Product features and positioning
- Trade channel spend
- Media spend
- Target market segment for decisions
Linear and Interger Programming In The Absence of Uncertainity
Powerful optimization technology is available to find the best solutions to complex problems faced by many organizations. Minimizing or maximizing an objective function which is dependent on variables such as costs, quantities, sales, price, profit while constrained by capacity, resources, dollars has been a well defined and utilized approach since the middle 1940s when logistics optimization mathematics were developed, known as linear and non-linear programming (LP) and integer (IP) programming. LP and IP models combined with AI algorithms will learn your business data and continuously maximize or minimize the objective function. We generally apply these optimization models to specific business challenges with low uncertainity to determine the most favorable outsome to the business problem.
- Objective function - defines the maximizing or minimizing function that we want to achieve
- Decision variables - parameters that can be controlled or adjusted to influence the outcome of the objective function
- Production quantities
- Resource allocation
- Cost of goods
- Revenue
- Scheduling
- Constraints - mathmatical expressions that limit the values or the relationships between decision variables
- Resource availability
- Capacity limits
- ERG requirements
Optimization Model Types
- Deterministic Optimization
- Solves problems with known parameters and with minimum uncertainty in the decision variables
Examples include linear programming (LP) and integer programming (IP)
- Solves problems with known parameters and with minimum uncertainty in the decision variables
- Stochastic Optimization:
- Operates with uncertainty or randomness in parameters
- Objective function and constraints involve probabilistic or random variables
- Nonlinear Optimization:
- Handles problems with nonlinear functions in the objective or constraints
- Commonly used in finance, engineering, and logistics
- Heuristics:
- Approximate problem-solving techniques when finding an exact optimal solution is computationally infeasible
- Applications:
- Operations Research: Optimize supply chains, production processes, and resource allocation, product pricing and revenue growth
- Finance: Portfolio optimization for better investment strategies, trade promotion management costs
- Logistics: Route optimization, inventory management, and scheduling, supply chain finance, matching demand and supply across a supply chain network
- Engineering: Design optimization, process improvement, and quality control
- Benefits:
- Cost Reduction: Optimized resource allocation minimizes costs
- Efficiency Improvement: Streamlined processes lead to better productivity
- Strategic Planning: Evaluate scenarios and alternatives for long-term decisions
Optimizing modeling with AI enables businesses to make data driven decisions, adopt new technologies, innovate and adopt to changing environments. With todays computational innovations and SAP transaction and master data modeled in HANA, SAC, PaPM significant upside potential exists for businesses to capture. An optimization model can have only one objective but can have many decision variable and constraints. For example if a company wants to optimize multipe key performance indicators such as profit, costs and resource allocation then we can choose one of the key performance indicators, like profit and treat the others as constraints.
Linear models are easier to optimize than non-linear models. Linear models involve constant parameters, multiplication products of decision variables and constant parameters and addition and subtraction. Non-linear models involve products of decision variables, ratios of decision variables, power or roots of decision variables, anything beyond a linear function.
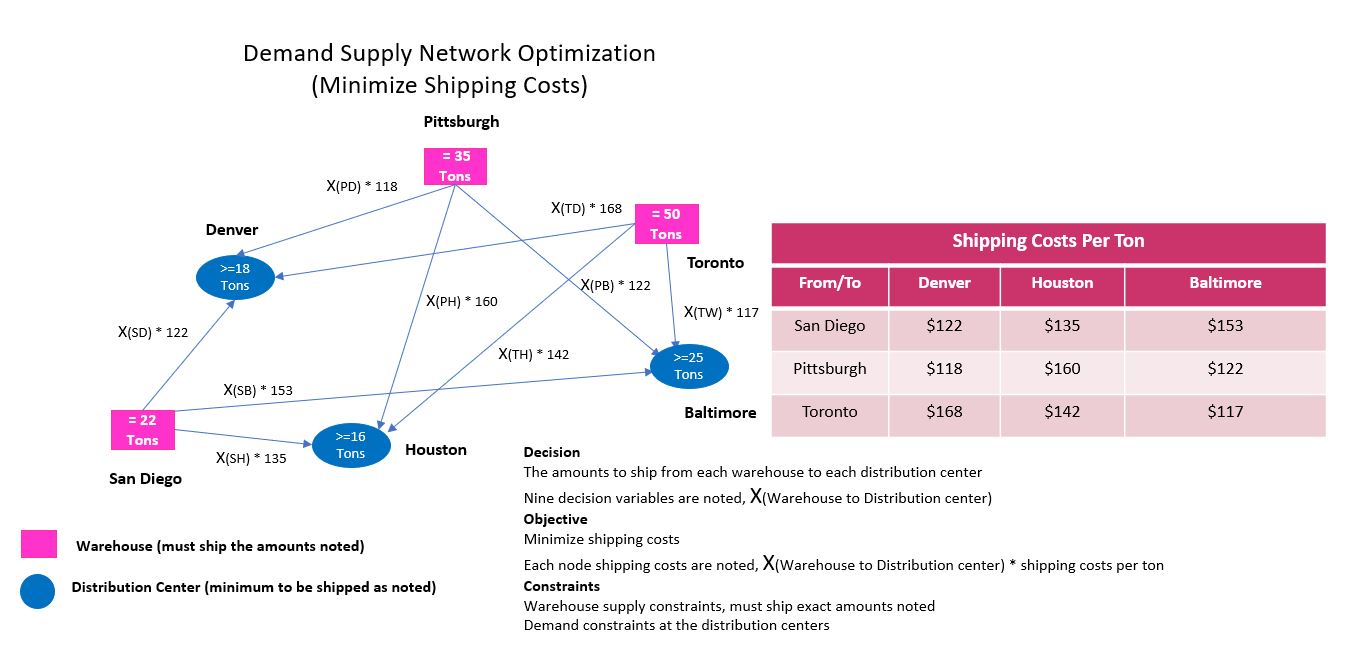
Simplified solver model optimizing demand supply objective with decision variables and constraints
- Details
- Written by: Douglas Berry
- Category: Pythagorean
- Hits: 782
Predictive analytics involves various algorithms and techniques to forecast future outcomes based on historical data. They are the backbone of operations research professionals, and now with AI are available to larger parts of an organization. These algorithms have been available for 50+ years yet not often are not deployed by a corporation. If used, most often they deployed in Excel, which is limited in the amount of data that can be ingested.
These algorithms need be deployed on large data sets, Hana, S4/HANA, BW, and Hadoop with BTP integration from multiple sources to be fully effective. With modern compute power and infrastructure, and with the integration of these algorithms to an AI tool, they can be effectively deployed.TekMetrix analyticA architectue uses AI LLM models optimized for software development to deploy these algorithms for highly value add process scenarios. Here are some of the key algorithms and techniques used.
What is a Sales Forecast Example?
Linear Regression
- Description: A statistical method that models the relationship between a dependent variable and one or more independent variables by fitting a linear equation to observed data.
- Use Case: Predicting sales volume, price, labor costs, material costs, commodity prices, stock prices, or any continuous outcome.
Logistic Regression
- Description: Used for binary classification problems, it predicts the probability of a binary outcome (e.g., yes/no, true/false).
- Use Case: Fraud detection, customer churn prediction, product quality
Decision Trees
- Description: A tree-like model of decisions and their possible consequences, including chance event outcomes, resource costs, and utility.
- Use Case: Classification and regression tasks, such as determining whether a customer will buy a product, new product introduction.
Random Forest
- Description: An ensemble learning method that constructs multiple decision trees during training and outputs the mode of the classes (classification) or mean prediction (regression) of the individual trees.
- Use Case: Improving accuracy and robustness over single decision trees.
Gradient Boosting Machines (GBM)
- Description: An ensemble technique that builds models sequentially, each new model correcting errors made by the previous ones.
- Use Case: High-performance tasks like ranking, classification, and regression.
Support Vector Machines (SVM)
- Description: A supervised learning model that analyzes data for classification and regression analysis by finding the hyperplane that best divides a dataset into classes.
- Use Case: Image recognition, text categorization.
Neural Networks
- Description: Computing systems inspired by the biological neural networks that constitute animal brains, capable of pattern recognition and learning from data.
- Use Case: Complex tasks like image and speech recognition, natural language processing.
K-Nearest Neighbors (KNN)
- Description: A non-parametric method used for classification and regression, where the input consists of the k closest training examples in the feature space.
- Use Case: Recommender systems, anomaly detection.
Time Series Analysis
- Description: Techniques that analyze time-ordered data points to extract meaningful statistics and other characteristics.
- Use Case: Forecasting stock prices, weather prediction.
- ARIMA (AutoRegressive Integrated Moving Average): Combines autoregression, differencing, and moving average models.
- Exponential Smoothing: Applies weighted averages of past observations to forecast future values.
Clustering Algorithms
- Description: Grouping a set of objects in such a way that objects in the same group (cluster) are more similar to each other than to those in other groups.
- Use Case: Market segmentation, image compression.
- K-Means Clustering: Partitions data into k clusters, each represented by the mean of the points in the cluster.
- DBSCAN (Density-Based Spatial Clustering of Applications with Noise): Finds core samples of high density and expands clusters from them
Data Modeling
Data in the CPG industry comes from a variety of sources including SAP sales and supply chain transaction data, marketing sources and customer behavior. The CPG industry is challenged with creating analytics on this data and using the data for predictive and optimizing purposes. The complexity lies in creating a data model. Without a proper knowledge of HANA columnar databases, open source databases and POS integration technology forecasting and analyzing SKU data is a challenge. Predictions that need be made are which customer is going to buy what product next, how many purchases are they going to make and what is the customer churn? What is my customer life time value, how often to they buy and when was the last time they bought a product. Other types of predictions include trade and promotions, pricing, conversion costs and marketing (sg&a) costs. TekMetrix tools are readily available for making these predictions and more. SKU level predictions can be made and structured into a P&L (SKU) level, cash flow and balance sheet. Analysis of the P&L and other financial documents can be done by SKU, customer, geography, brand and other attributes, including aggregations. We can forecast into the future your customer lifetime value (CLV).
The question becomes, how to design and develop an underlying data model supporting a variety of analytics and predictive metrics including embedding AI and ML capabilities into the underlying data model? TekMetrix data AI ML models and experience will accelerate your project timelines and add significant value to your business.
Defining the Right Questions
If you want to run your business most effectively, we need to make predictions about the future. Predictive analyical forecasting takes historical data and creates a one or multi period forecast. TekMetrix data analysis helps examine past performance and also helps to predict future performance, for example predicting questions like:
- Customer purchases
- Customer life time value
- Warehouse inventory
- Cost of goods sold
- Revenue
- Customer returns
- Pricing
- Trade promotion costs
- Contribution margin impact of incremental sales due to trade promotions
We want to make "when will" predictions for a fixed period and multiple periods in the future.
- Inherently granular
- Customer behavior
- Foward looking
- Multi-platform
- Broadly applicable
- Multidisciplinary
Predictive Statistics
Predictive statistics uses statistics for prediction and forecasting generally one period ahead of the current period. The mean of the prediction is the sample mean which is an unbiased estimation of the mean of true demand distribution. Standard deviation for prediction needs to be adjusted if there is insufficient data. If the data is normally distributed than the data can be adjusted for predictive purposes.
If there is a trend in the data, than moving averages, mean and standard deviation computations used for predictive purposes will lag the trend. Therefore, linear regression or exponential smoothing are additional forecast options.
Regression Example - Predict 1 Period Ahead of the Current Period
The regression equation and its variants are used in Artificial Intelligence (AI) and Machine Learning (ML) modeling. These equations help us understand the relationship between independent variables (features) and a dependent variable (target) by fitting a mathematical function to the data. Various types of regression models, such as linear regression, polynomial regression, and logistic regression, are commonly employed for prediction, classification, and modeling tasks. These models can be developed in SAP HANA, SAC, PaPM. Additional tools could be MatLab, R, Python, or for smaller models in Excel.
- Revenue growth management, as an example can be optimized using regression analysis. Optimal pricing is the price which optimizes overall profit. Models are built to:
- Quantify sales demand at different prices
- Find the optimal price
- Optimization performed with the general regression formula: Y(n) = a + b1X1(n) + b2X2(n) + .... bjXj(n) + E(n) , X values are independent of Y and E(n) it error
- Multiple independent variables can be modeled, for example Sales = a + b1(Price) + b2(Advertising) + E
- The regression equation and variants of the regression equation are used for AI and ML modeling
Key Performance Indicators Use In Forecasting Beyond Period 2:
- Direct marketing example using regression analysis can be used to predict future, multiperiod, customer behavior:
- Use key performance indicators of past customer behavior to predict future behavior
- Regression models are also useful for this type of modeling and forecasting
- Regression model predictions using RFM models are used to forecast customer behavior (recency, frequency, monetary value)
- Recency - what were the recent customer purchases (more important than frequency)?
- Frequency - how many purchases did the customer make (more important than monetary value)?
- Monetary value - what is the value of each of the purchases?
- Probability models can be used to forecast longer term horizons
- Buy till you die models (BTYD) are a powerful probabilistic model used to make long range projections, to answer when type questions, when will a customer churn?
- Customer lifetime value modeling using Pareto/NBD and BG/BB models
- Limitations of regression models
- Forecasting more future periods than period 1 beyond the current period, regression models are limited because they need input data
- Making predictions for period 3 than period 2 data can be used as the independent variable
- Regression models are limited based on the data that is available to forecast multiple periods into the future
Sales Forecast Example
AI integration with Corporate Data and Linear Regression:
- Data Collection: Gather your historical sales data, including variables that might influence sales, such as marketing spend, seasonality, and economic indicators.
- Data Preprocessing: Clean and prepare the data for analysis. This involves handling missing values, encoding categorical variables, and scaling numerical features, unnecessary data from the data model, billions of records are sufficient.
- Feature Selection: Identify the independent variables (predictors) that are most relevant to predicting the sales. This might be total advertising spend, average product price, or number of holiday promotions.
- Model Training: Use the cleaned and preprocessed data to train the linear regression model. Copilot can help automate this by fitting the linear equation y=b0+b1x1+b2x2+...+bnxn, where y is the dependent variable (sales), and x1,x2,...,xn are the independent variables.
- Model Evaluation: Assess the performance of the model using metrics like R-squared and Mean Squared Error (MSE) to ensure it accurately predicts sales based on the input features.
- Prediction: Use the trained model to make predictions on new data. This is where AI can shine, taking the input variables and outputting a sales forecast.
By managing these steps, TekMetrix AI integration can streamline the entire process of creating and continuously updating a sales forecast. Let’s say we have billions of records in S4-BW4/HANA. We input the data along with variables like marketing spend, holiday seasons, supply chain cycle times, availabilities and econometrics. TekMetrix AI preprocesses the data, selects the best predictors, trains the forecast model, evaluates model performance and then uses it to forecast next month’s sales.
- Details
- Written by: Douglas Berry
- Category: Pythagorean
- Hits: 929
Business Context of Advanced Machine Learning
Across the globe businesses are facing intense competitive pressure. The cost of raw materials, manufacturing conversion costs and transport costs are volatile and are all rising. Supply remains volatile and demand from customers is harder and harder to predict. New channels provide as many challenges as they do opportunities and the imperatives of ESG to reduce environmental impacts cannot be ignored. Forecasting is not as difficult as it once was, given the maturity of today’s compute power, database and AI ML modeling tools. Customers require product SKU level forecasting both in terms of quantity and in dollars, and the source of the forecast data resides in the SAP HANA databases.
Product SKU level dollar forecasting requires price, volume, COGS and SG&A be modeled as a P&L, Balance Sheet and Cash Flow. TekMetrix SAP data models using PaPM, HANA, SAC, BW4 and S4, and a properly scaled AI tool from SAP BTP are used to assist not only in the forecast but in the automation of the forecasting process. The future of corporations includes more products ranges, more channels, more suppliers and more distribution centers. More international shipping. The enterprise landscape includes SAP and non-SAP ERP systems, business warehouses, cloud and on-premise systems, success factors, Ariba, Azure, WAS and other cloud services. Data sets can be large to very large involving billions of records that the forecast is created on.
Historical Approach to Forecasting
Subjective Forecasting Methods
- Composites, customer surveys, forecast experts, and Delphi methods are examples of subjective forecasting methods.
- Composites - aggregation of data such as sales from the sales force, election polling
- Customer surveys - the forecast is based on customer feedback
- Forecast experts - the forecast is prepared by a limited number of experts
- Delphi method - individual opinions iterative complied and reconsidered until the group reaches a consensus
Objective Forecasting Methods
Time Series Forecasting
Historically, the approach to forecasting relies on time series analysis looking to identify patterns, trends and seasonality in demand. Moving averages and exponential smoothing are commonly used in time series forecasting. The goal of time series analysis is to isolate patterns in past data. The data in time series forecasting will have descriptive characteristics like trend, seasonality or cycles and randomness that are used for prediction. Other, qualitative methods have been used. These are techniques based on expert opinions and market research. Delphi methods, market surveys and focus groups are examples of qualitative techniques. Time series methods use historical data as the basis of estimating future outcomes. Time series forecasting is based on the assumption that past demand history is a good indicator of future demand:
- Moving average
- Weighted moving average
- Exponential smoothing
- Autoregressive moving average (ARMA)
- Autoregressive integrated moving average (ARIMA - Box Jenkins)
- Extrapolation
- Linear regression
- Trend isolation
- Growth curve
- Recurrent neural network
Causal Models
Causal models are explained through causal analysis. Causal models establish relationships between demand and demand drivers, such as economic indicators, supply and capacity constraints, new product introductions, advertising expenditures or competitor activities. Causal models require the Demand Value (DV) be formulated as a function of all "n" causes. These models often involve regression analysis and can provide insights into how certain factors influence demand. This brings much more richness to the forecast but is typically done on an ad-hoc basis rather than dynamically. Causal models include:
- Aggregate forecasts using Cooke’s method
- Technology forecasting
- Statistical surveys
- Scenario building
- Forecast by analogy
- Delphi methods
Probability Distributions
Discrete probability distributions are probability distributions that assign probabilities to each individual outcome. Examples of discrete probability distributions include the binomial distribution, the Poisson distribution, and the hypergeometric distribution. Continuous probability distributions are probability distributions that assign probabilities to intervals. Examples of continuous probability distributions include the normal distribution, the t-distribution, and the chi-square distribution.
The main difference between discrete and continuous probability distributions is that discrete probability distributions define probabilities associated with discrete variables, while continuous probability distributions define probabilities associated with continuous variables. A discrete variable is a variable that can only take on a finite or countably infinite number of values, while a continuous variable is a variable that can take on any value between two specified values.
Commonly Used Discrete Probability Distributions:
- Geometric distributions:
- Used to model the number of trials needed to get the first success in a sequence of independent and identically distributed Bernoulli trials
- Binomial distributions:
- Used to model the number of successes in a fixed number of independent and identically distributed Bernoulli trials
- Bernoulli distributions:
- Used to model the outcome of a single Bernoulli trial, which is a random experiment with two possible outcomes
Commonly Used Continuous Probability Distributions:
- Normal distributions:
- Used to model continuous variables that are symmetric and bell-shaped
- Describes the distribution of future relative changes in, for example, demand, stock valuations and FX rates.
- Exponential distributions:
- Used to model the time between events that occur randomly and independently at a constant average rate
- For example, exponential distributions may be used to characterize time between successive arrivals of customers in customer services systems, call centers
- Beta distributions
- Uniform distributions:
- Used to model continuous variables that are equally likely to occur over a specified range
Discrete probability distribution forecasting
An annual operating plan, (AOP) represents the forecast metrics to measure and match demand and supply in uncertain situations. An understanding of the variations in the forecast data is needed to answer how much to produce and at what cost within acceptable accuracy limits. A problem with matching demand and supply in uncertain situation is called a Newsvendor, newsboy or single-period forecasting problem. Fixed prices and uncertain demand are attributes of the demand problem. Solutions to the problem are used to create optimal inventory levels. Demand is a random variable.
A typical problem situation, modeling an uncertain future demand, requires a mathematical and data model. With the proper data model, we will describe a discrete probability distribution with mean and standard deviation. A discrete variable is a variable that can take on a finite or countably infinite number of values. Examples of discrete variables include the number of children in a family, the number of cars sold by a dealership, and the number of heads obtained when flipping a coin, the number of items in inventory. The table below depicts how the modeling process might begin for a discrete probability distribution.
Discrete Probability Distribution Using SKU Demand Case Scenarios

This is a Pythagorean mean and standard deviation. There are other Pythagorean means we don't describe here. The discrete probability distribution, mean and standard deviation describes on average the deviation from the demand data values from the mean. All possible values of the discrete random variable, are forecast along with their probabilities. Examples of discrete probability distributions include a binomial distribution, Poisson distribution and hypergeometric distributions.
Continuous probability distributions forecasting
Continuous probability distributions are used to forecast a continuous random variable where the random variable, demand, DV in this case, can take on an interval of values; groups of values. A continuous variable is a variable that can take on any value within a specified range (which may be infinite). Examples of continuous variables include height, weight, temperature, and time. A normal distribution is an example of a continuous probability distribution. The random variable can take on any values. In our use case, we will use values of the SKU demand case, DV within specified interval values of minus DVmin to plus DVmax, (-DVmin to +DVmax). A cumulative distribution function is used for statistics prediction or forecasting. The mean is simply the sum of the DV's divided by the number of DVs. The standard deviation for prediction is = StdDEV = StdDEV/√n where n = the total number of data points. The more data points we have then descriptive statistics for demand forecasting approaches that of predictive statistics. Examples of continuous probability distributions include normal distributions, uniform distribution and exponential distributions.
Forecast error can be measured as the difference between the forecast value and the actual value, DVerror = DV forecast -DV actual. There are generally 3 ways to measure forecast error:
- Mean Absolute Deviation (MAD) = Σ|DVerror|/n
- Mean Squared Error (MSE) = ΣDEVerror^2/n
- Mean Absolute Percentage Error (MAPE) = Σ |DVerror /DV per period|/n X100
Forecast bias is the average value of DVerror tends to be positive or negative. Thus, it is a measure of under or over forecasting.
Continuous Probability Distribution Using SKU Demand Case Scenarios


Seasonal Forecasting
Trends and Seasonality
If there is a significant trend (positive or negative), and or seasonality in the demand values then the moving averages will lag the trend. When there is an increasing trend than moving averages will usually fall below the demand. When there is a decreasing trend moving average forecasts will usually fall above the demand. When trend is present linear regression methods can be used. Fitting a best fit trend line is usually done with Ordinary Least Squares (OLS). Below we show a calculated trend line on 60 periods of data. The dotted trend line shows the best fit line through the data. The forecast, for the next period, is calculated from the trend line equation, shown below as Y = 27657*X +2E+06. Seasonality is a pattern in the data that is repeated at regular intervals. Multiplicative seasonal factors are represented by Di (D1, D2, D3,.....Dn) where i represents the season and n denotes the total number of seasons. Note that ΣD(i) = N the total number of seasons. If D(i) = 1.3 than this implies that the season is 30% higher than the baseline average. And if D(i) = .75 then the implication is that the season is 25% lower than the base line average.

To estimate seasonal factors, follow these steps:
- Calculate the sample mean
- Calculate the seasonal averages
- Calculate the seasonal factors:
- Divide the seasonal averages in step 2 by the sample mean and sum the resulting N numbers, the sum of the resulting N numbers will correspond to N seasonal factors
- De-Seasonalize by dividing each observation in the data by the appropriate seasonal factor


Once the model has created the seasonal and de-seasonalized values the forecast can be completed using the de-seasonalized series as a moving average. Multiply the de-seasonalized moving average by the appropriate seasonal factor. This will create a final forecast.
Normal Distribution Forecast for New Product Introduction
How to forecast the demand for a new product when there is no historical data? To create a new product forecast subjective methods, described above, could be used; the Delphi method for example. To improve the forecast we can create a normal distribution forecast using SAP SKU level data from other similar products. We create a data model with Product, Forecast, Produced, Sales and Actual Demand as shown in the table below. Forecast accuracy is calculated as the ratio of Actual / Demand. The normal distribution demand curve for the new product is calculated as:
- Begin with an initial forecast generated from subjective methods (sales inputs, intuition, experience)
- Forecast accuracy = A/F ratio = Actual demand / Demand forecast
- Mean = Expected actual demand = Expected A/F ration * Demand Forecast
- Standard deviation = Actual demand = A/F Ratio * Forecast
- Correct the standard deviation = Standard deviation / Standard deviation * (SQRT(number of demand periods)), as n becomes larger the correction term disappears
New Product Forecasting Technique for a subjective demand of 1000 units

New Product Forecasting Technique with Normal Distribution

TekMetrix Forecasting
Machine learning has revolutionized demand forecasting by automating the calculations required to analyze data sets, identify hidden patterns and adopt to changing trends. TekMetrix SAP data models combined with ML algorithms can analyze vast amounts of data. The compute power to perform this type of SKU forecasting has been made more widely available and easier due to the SAP simplified data model. Some of the most used machine learning techniques for demand forecasting is:
- Random forecasting
- Gradient boosting
- Long short-term memory networks (LSTM)
- Autoregressive integrated moving average (ARIMA) statistical models
- Neural networks
- Group method of data handling
- Support vector machines
A good forecast is more than a single number. Forecast data can come from experts in the organization and from historical data. Forecast accuracy is significant driver of business performance. And, annual operating plan, (AOP P&L, Balance Sheet, Cash Flow) is a key forecast metric used by planners to match demand and supply. Forecasting is performed against conditions of uncertainty. An understanding of the variations in the forecast data is needed to the answer the question "how much to produce and when". Accuracy limits are described using TekMetrix statistical analysis.
A typical problem situation, requiring a forecast mathematical and data model is:
- Retailer orders from a supplier and sells to customers
- The ordered products are placed on the store shelf
- Customers in the store buy the produce if it is available on the shelf
- To ensure availability the order needs be placed before the customer demand is known
- There is one chance to order inventory
- Manage trends and seasonality
- This problem of matching demand and supply in uncertain situation is called a Newsvendor, newsboy or single-period forecasting problem. Fixed prices and uncertain demand are attributes of the demand problem. Solutions to the problem are used to create optimal inventory levels which drives the AOP P&L priorities.
Business challenge:
- No visibility into demand
- Orders are placed prior to seeing the actual demand
- Incorporating data from diverse sources including SAP S4 transactions, customer behavior, economic indicators, marketing efforts, weather, events and competitor information
Characteristics of SKU good forecasting:
- Point forecasts usually wrong because demand can be a random variable
- Forecasts should include some distribution of information:
- Mean and standard deviation
- Range (high and low)
- Aggregate SKU forecasts are usually more accurate
- Data modeling in HANA with historic data, current FY transactions meshing with consumer data
- Use advanced machine learning algorithms
Solution process using a continuous probability distribution:
- Choose the right forecasting algorithm
- Model training and tuning
- Forecast at various levels
- Analyze past demand data using a probability distribution
- Follow structured data analysis process (Newsvendor analysis)
- Communicate the objective (usually maximize profit, minimize costs or increase market share)
- Perform a statistical analysis, communicate accuracy metrics
- Capture actual demand and realized profits and costs (too little or too much inventory)
- Repeat for each new plan period while continuous monitoring and updating
SKU Level Customer Revenue Plan and Forecast with SAP S4 - HANA - SAC Tools
TekMetrix SKU Forecasting and Analytics:
- Customer supply and order management
- Customer order analysis and forecasting
- Customer SKU level profitability (P&L)
- Market analysis and segmentation
- Customer analysis
- Product pricing, pricing elasticity
- Customer experience
- Customer key purchasing criteria
- Product lifecycle
- Product substitutions
- Sales promotion planning, forecasting, analytics
- Adoption cycle
- Competitor analysis
- Social and sentiment analysis
- Digital commerce
- Category and panel trends
- SAP advanced trade management analytics (ATMA)
- Digital commerce
- KAM analytics
- Product SKU level profitability (AOP P&L, balance sheet, cash flow)
- Supply chain analytics (warehousing, manufacturing, procurement, finance, distribution, HR, inventory, scheduling, forecasting)
- SAP S4-BW4-CRM-SAC-PaPM-HANA-Hadoop-AnyDB data modeling and analytics